倒排索引是搜索引擎常用的一种检索匹配方式,也是被验证为搜索单词到数据文档映射关系的最佳实现方式之一。阿里巴巴国际站也不例外,国际站的搜索系统算法也遵循SEO搜索逻辑的底层理念,比如阿里的HA3搜索引擎就使用了倒排召回,正排过滤,粗排算分等计算逻辑模块。也是有小伙伴问祥助阿里搜索引擎的一个标题抓取思路是怎么样的,所以这篇文章为主的祥助用搜索引擎的SEO处理逻辑机制分享一下倒排索引的思路逻辑,帮助大家更好的理解搜索系统的抓取排名是怎么样的一个逻辑思路。


搜索引擎原理
首先搜索引擎,包括阿里巴巴搜索系统的总体思路都是:搜索蜘蛛Spider开始出发,对全网的页面/商品进行从爬取-解析-索引-排名的流程。我们常说的爬虫或蜘蛛,就是这么一个可爱的处理小机器人。可以把全网理解为一个庞大的蜘蛛网,上面遍布着很多页面/产品,这个搜索小爬虫会顺着蜘蛛网进行爬取,获取这些页面/产品的信息。
比如祥助在搜索框输入power bank这个关键词并点击search按钮,当系统接收到祥助发起的这个查询请求时,主要会经过下列的流程化路径:
- 搜索系统的分词模块引擎对祥助发起的原始Query查询请求(即power bank)进行分析,产生对应的terms,存储到数据表。
- terms在倒排索引中的词项列表中查找对应的terms的结果列表。
- 对结果列表数据进行微运算,如:计算文档静态分,文本相关性,类目相关性等。
- 应用深度模型算法引擎,进行线性聚合处理,产品去重,店铺打散等深度操作。
- 基于上述运算的最终综合得分对文档进行综合排序,最后返回结果给用户。
当然这个是简化的流程,还有很多细化的操作模型比如千人千面逻辑下的各种标签和特征的识别以及判断。其中倒排索引也就是开端针对搜索Query查询的分词和分析是很重要的一步,这个也是大家写标题的时候会产生的疑问点,我写的标题,搜索系统是怎么进行处理的呢?

倒排索引原理
首先搜索引擎使用倒排索引(Inverted-index)来组织数据,会将词进行拆分分析来对比文档进行匹配,或者说产品/页面。比如检索关键词后有两个结果页面或者说商品页面。
{"id":1,"title":"I love google search engines.","tag":12345}
{"id":2,"title":"I search keywords in google.","tag":54321}搜索系统对这两个检索到的title标题会 可以分词为
- "I / love / google / search / engines”
- "I / search / keywords / in / Google "
搜索引擎或者说搜索系统会将祥助检索结果页面的2个示例页面/产品的标题进行分词操作,得到的每一个词元,比如说"love",称作一个term,那么倒排索引存储的数据将会变成:
| title | |
| term | 文档id |
| I | 1,2 |
| love | 1 |
| Search | 1,2 |
| engines | 1 |
| Keywords | 2 |
| In | 2 |
| 1,2 |
搜索引擎将上述标题进行拆分和数据存储后,搜索引擎会使用倒排索引的引擎来进行模糊匹配,以上文为例,祥助输入"google search engines"执行Query查询搜索行为时:
- 首先输入词也进行分词"google/search/engines",然后用得到的term去和前面存储的索引数据结构进行比对,得到:"google"->{1,2},“search”->{1,2}," engines "->{1}
- 然后google-search-engines->1得到文档1为结果,这样就完成了针对祥助搜索需求的一个匹配模型。
简单来说,正排索引(forward index)是通过文档id或者主键id查询具体文档内容(单词列表)
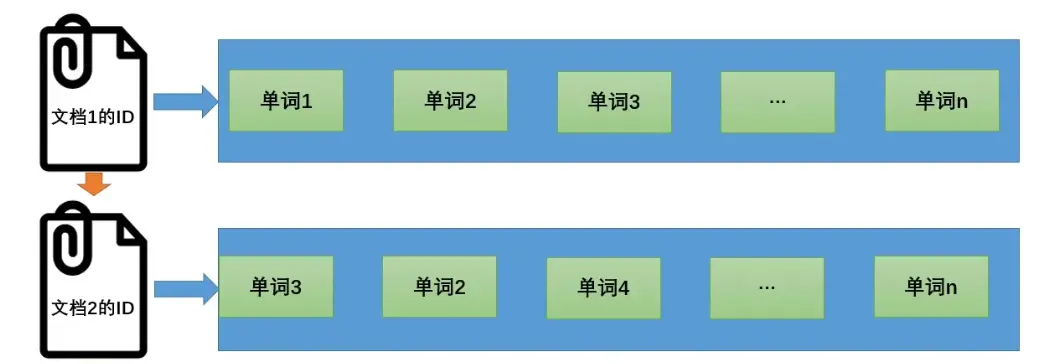
正排索引结构图
倒排索引(inverted index),根据单词快速获取包含这个单词的文档列表。与正排索引的查找逻辑相反。通过分词器来将文档进行分词,建立单词树提高单词查找效率,然后存储单词和文档的对应关系。

引用知乎上一张很形象的图,就很好理解倒排索引。有些技术类的工具书籍会在书本末尾提供一页索引页,标注哪些常搜索的关键词,对应哪些页码。这就是倒排索引的一个经典应用案例,通过关键词,可以快速定位到对应的文档(页面页码)。

那么问题来了,因为祥助搜索的是google search engines,而页面标题也含google search engines,这个词的结构都是一致的。但是我们说阿里有广泛模糊匹配模式,客户搜索的词在产品的标题不一定是完全一样出现的。这就涉及到一个匹配模糊度的问题了。

祥助举个例子,假如阿里设置搜索引擎系统的匹配度为100%,依旧输入"google search engines",如果匹配度是100%,那么结果就是含google search engines这个query查询词的搜索结果判断={1},如果匹配度降到60%(搜索词越短,其范围越模糊),那么结果可以是:
"google"+"search,"google"+"engines","search"+"engines"={1,2}
在一些在线产品数不足的搜索场景下,搜索一个关键词A出现的产品排名,会发现标题里并没有关键词A的全部结构,而是取部分交集甚至完全没有出现关键词A(无商家做这个词的产品覆盖)
倒排索引的匹配度可以通过以下方式来实现:
- 完全匹配:搜索词与文档中的关键词完全匹配,即搜索词中的所有关键词都在文档中出现。
- 部分匹配:搜索词与文档中的部分关键词匹配,即搜索词中的一部分关键词在文档中出现。
- 位置匹配:搜索词与文档中的关键词在相近位置匹配,即搜索词中的关键词在文档中相邻或接近的位置出现。
也就是说,搜索引擎的匹配度的不同,涉及到搜索词与文档内容的匹配程度。 匹配度较高时,搜索结果需要严格包含所有搜索词元,即搜索词元必须全部出现在文档中,这样的匹配方式可以确保搜索结果与用户的搜索意图高度相关。
而当匹配度降低时,搜索结果可能会包含部分匹配的情况。这时搜索引擎系统会根据搜索词元的不同组合,取交集或者部分交集来匹配文档内容,以提供更广泛的搜索结果。
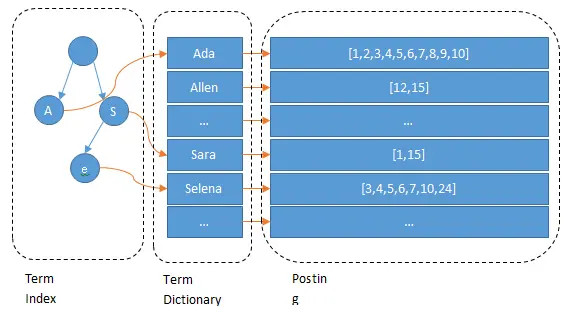
在匹配度较低的情况下,搜索结果可能包含部分搜索词元,而不是全部搜索词元,这样可以扩大搜索结果的范围,但也可能导致一些不太相关的结果出现。
模糊匹配
其中有个细节要注意,比如祥助如果只搜索engines,搜索词的长度和结构很短,那么匹配度会降级降低,只要有一个term符合匹配就会输出当作结果。

所以阿里的相关性计算会加入很多非相关性特征,也可以理解为文本相关性是硬特征,也是最初始的匹配特征。Power bank这个产品词绝大部分商家都能在文本相关性上用对,做到倒排索引,正排过滤,类目正确等都不会出现产品存在错误问题。
所以为什么阿里巴巴的信保模型,买家行为等对排名很重要,也是因为不管是倒排索引,类目正确等文本相关操作,商家都不容易犯错,都容易做到优秀。那搜索系统怎么判断谁排前面呢?那就要加入软特征来做甄别了。哪个产品的信保走的多,点击率高,买家标签和商品SKU标签匹配计算等,就是附加的深度匹配模型计算的流程了。